Extracting Data#
There are a number of ways to instantiate a new Dataset object, but all of them require the data to be loaded into memory first. Some common formats you'll find data in are structured plain-text such as CSV or NDJSON, or in a queryable database such as MySQL or MongoDB. No matter how your data are stored, you have the freedom and flexibility to implement the data source to fit your current infrastructure. To help make extraction simple for more common use cases, the library provides a number of Extractor objects. Extractors are iterators that let you loop over the records of a dataset in storage and can be used to instantiate a dataset object using the fromIterator() method.
CSV#
A common plain-text format for small to medium-sized datasets is comma-separated values or CSV for short. A CSV file contains a table with individual samples indicated by rows and the values of the features stored in each column. Columns are separated by a delimiter such as the , or ; character and may be enclosed on both ends with an optional enclosure such as ". The file can sometimes contain a header as the first row. CSV files have the advantage of being able to be processed line by line, however, their disadvantage is that type information cannot be inferred from the format. Thus, all CSV data are imported as categorical type (strings) by default.
Example
attitude,texture,sociability,rating,class
nice,furry,friendly,4,not monster
mean,furry,loner,-1.5,monster
The library provides the CSV Extractor to help import data from the CSV format. We'll use it in conjunction with the fromIterator() method to instantiate a new dataset object. In the example below, In addition, we'll apply the Numeric String Converter to the newly instantiated dataset object to convert the numeric data to the proper format immediately after instantiation.
use Rubix\ML\Datasets\Labeled;
use Rubix\ML\Extractors\CSV;
use Rubix\ML\Transformers\NumericStringConverter;
$dataset = Labeled::fromIterator(new CSV('example.csv', true))
->apply(new NumericStringConverter());
JSON#
Javascript Object Notation (JSON) is a standardized lightweight plain-text format that is used to represent structured data such as objects and arrays. The records of a dataset can either be represented as a sequential array or an object with keyed properties. Since it is possible to derive the original data type from the JSON format, JSON files have the advantage of importing the data in the proper type. A downside, however, is that the entire document must be read into memory all at once.
Example
[
{
"attitude": "nice",
"texture": "furry",
"sociability": "friendly",
"rating": 4,
"class": "not monster"
},
[
"mean",
"furry",
"loner",
-1.5,
"monster"
]
]
The JSON extractor handles loading data from JSON files.
use Rubix\ML\Datasets\Labeled;
use Rubix\ML\Extractors\JSON;
$dataset = Labeled::fromIterator(new JSON('example.json'));
NDJSON#
Another plain-text format called NDJSON or Newline Delimited Javascript Object Notation (JSON) can be considered a hybrid of both CSV and JSON. It contains rows of JSON arrays or objects delineated by a newline character (\n or \r\n). It has the advantage of retaining type information like JSON and can also be read into memory efficiently like CSV.
Example
{"attitude": "nice", "texture": "furry", "sociability": "friendly", "rating": 4, "class": "not monster"}
["mean", "furry", "loner", -1.5, "monster"]
The NDJSON extractor can be used to instantiate a new dataset object from a NDJSON file. Optionally, it can be combined with the standard PHP library's Limit Iterator to only load a portion of the data into memory. In the example below, we load the first 1,000 rows of data from an NDJSON file into an Unlabeled dataset.
use Rubix\ML\Extractors\NDJSON;
use Rubix\ML\Datasets\Unlabeled;
use LimitIterator;
$extractor = new NDJSON('example.ndjson');
$iterator = new LimitIterator($extractor->getIterator(), 0, 1000);
$dataset = Unlabeled::fromIterator($iterator);
SQL#
Medium to large datasets will often be stored in an RDBMS (relational database management system) such as MySQL or PostgreSQL. Relational databases allow you to query large amounts of data on-the-fly and can be very flexible. PHP comes with robust relational database support through its PDO interface. The following example uses PDO and the fetchAll() method to return the first 1,000 rows of data from the patients table. Then, we'll load those samples into an Unlabeled dataset object using the standard constructor.
use Rubix\ML\Datasets\Unlabeled;
$pdo = new PDO('mysql:dbname=example;host=127.0.0.1');
$query = $pdo->prepare('SELECT age, gender, height, diagnosis FROM patients LIMIT 1000');
$query->execute();
$samples = $query->fetchAll();
$dataset = new Unlabeled($samples);
Images#
PHP offers a number of functions to import images as PHP resources such as imagecreatefromjpeg() and imagecreatefrompng() that come with the GD extension. The example below imports the .png images in the train folder and labels them using part of their filename. The samples and labels are then put into a Labeled dataset using the build() factory method and then converted into raw color channel data by applying the Image Vectorizer.
use Rubix\ML\Datasets\Labeled;
use Rubix\ML\Transformers\ImageVectorizer;
$samples = $labels = [];
foreach (glob('train/*.png') as $file) {
$samples[] = [imagecreatefrompng($file)];
$labels[] = preg_replace('/[0-9]+_(.*).png/', '$1', basename($file));
}
$dataset = Labeled::build($samples, $labels)
->apply(new ImageVectorizer());
Missing Values#
By convention, missing continuous feature values are denoted by the NAN constant and missing categorical values are denoted by a special placeholder category (ex. the ? category). Dataset objects do not allow missing values of image or other data types.
$samples = [
[0.01, -500, 'furry'], // Complete sample
[0.001, NAN, 'rough'], // Missing a continuous value
[0.25, -1000, '?'], // Missing a categorical value
];
Converting Formats#
It may be useful to convert a dataset stored in one format to another format. In the example below we'll use the CSV extractor to read the data from a file in CSV format and then convert to NDJSON format using the toNDJSON() method on the Dataset object. Then we'll write the returned encoding to a file on disk by specifying the path as an argument to the write() method.
use Rubix\ML\Datasets\Labeled;
use Rubix\ML\Extractors\CSV;
Labeled::fromIterator(new CSV('example.csv'))
->toNDJSON()
->write('example.ndjson');
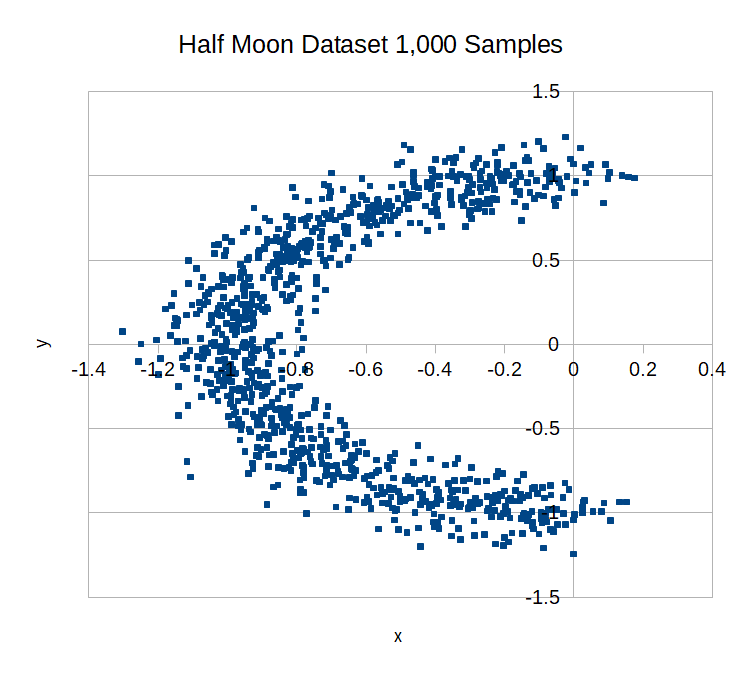
Synthetic Datasets#
Synthetic datasets are those that can be generated by one or more predefined formulas. In Rubix ML, we can generate synthetic datasets using Generator objects. Generators are useful in educational settings and for supplementing a small dataset with more samples. To generate a labeled dataset using the Half Moon generator pass the number of records you wish to generate to the generate() method.
use Rubix\ML\Datasets\Generators\HalfMoon;
$generator = new HalfMoon();
$dataset = $generator->generate(1000);
Now we can write the dataset to a CSV file and import it into our favorite plotting software.
$dataset->toCSV(['x', 'y', 'label'])->write('half-moon.csv');